









- Setup and management of virtual machines to host third-party imaging software with specific hardware and software requirements
- Assisting vendors with the setup of third-party compute clusters
- Cloud resource auditing
- Analysis to support publications
The BI team has been responsive, flexible, and well-organized, and this has enabled our small internal team to focus our efforts on supporting our drug development programs.”
When to use bioinformatics?
Bioinformatics has a huge number of applications. It can be used to analyze all kinds of large biological datasets that present a seemingly impossible task to do using Excel or other low-throughput approaches.
What is cloud computing?
Cloud computing is a broad term encompassing data management, data storage, software, and other services and resources hosted on a digital infrastructure platform using the internet.
What is an analytical pipeline?
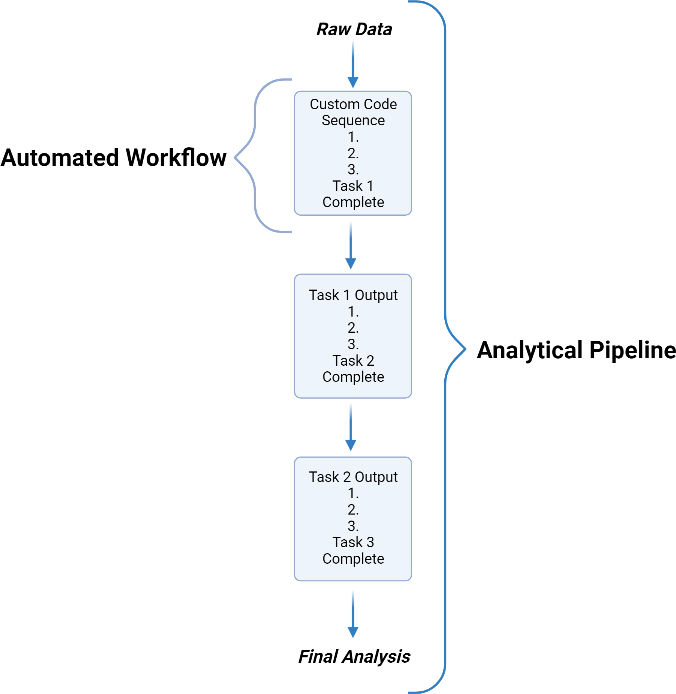
An analytical pipeline is a series of bioinformatic or analytical tasks, in the form of scripts or code, that are run in a predetermined sequence to perform an analysis. Analytical pipelines are rigorously tested to ensure reproducible and reliable results.
What is bioinformatics as a service (BaaS)?
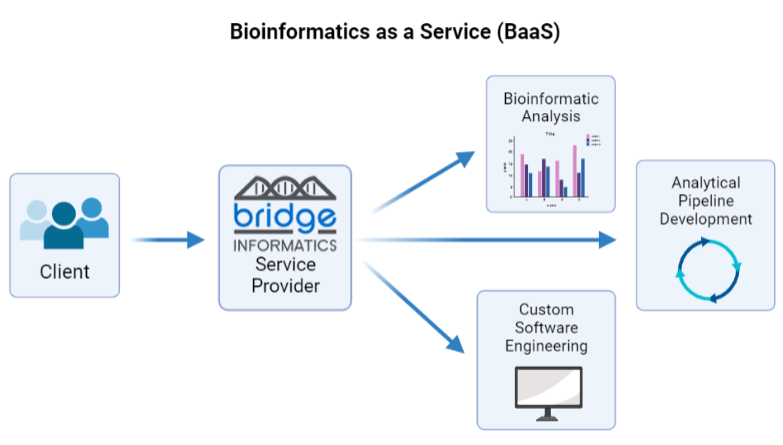
BaaS involves bioinformaticians, software engineers, and other data scientists, many with years of wet lab experience, working with biologists to create computational tools needed to address a given biological problem. Examples of BaaS are the analysis of single-cell and bulk next-generation sequencing (NGS) data, literature-driven data mining, and custom bioinformatics training for clients. BaaS providers vary in how they execute these tasks – at Bridge Informatics, we provide bioinformatics services in three main areas. The first is bioinformatic analysis, where we can utilize the power of bioinformatics to identify genomic factors that lead to disease, including biomarkers of disease, drug response, and more. Second is analytical pipeline development- see “What is an analytical pipeline?” Third is custom software engineering- see “What is custom-tailored software?”
What is infrastructure as a service (IaaS)?
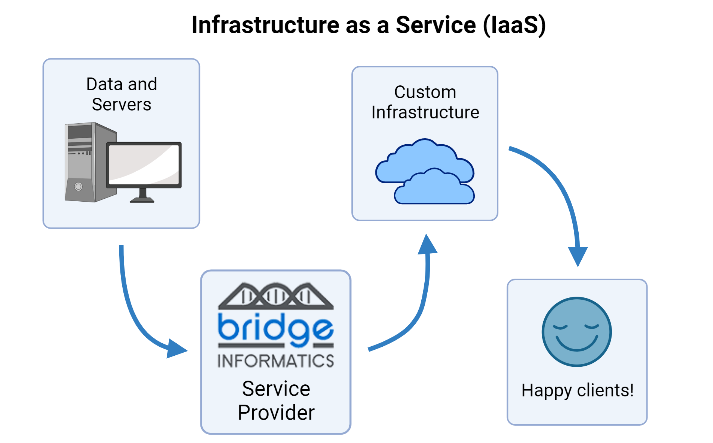
Infrastructure as a service (IaaS) is the creation of on-premise or cloud-based data storage and infrastructure (aka data organization, access, optimization, and integration) custom-tailored to a client’s needs. Service providers like Bridge Informatics have specialists that can create a custom infrastructure for optimal data storage and protection. A quality cloud or hybrid data infrastructure allows for more efficient data collection, storage, sharing, reproducibility, and overall collaboration. IaaS is an essential service for modern life science companies. If you’re curious, book a free discovery call to discuss how we can create custom tools for your data analysis needs.
What are the advantages of bioinformatic services?
In the era of NGS and omics data, a collaboration between bench biologists and computer scientists is essential to uncover new findings and hidden insights. Outsourcing these bioinformatic tasks to Bridge Informatics has many advantages:
- Working with computational scientists who actually “speak biology” and will bridge the gap between the dry and wet lab.
- Saving time for bench researchers and for in-house data scientists.
- Improved quality and reproducibility of results.
- Expertise of BaaS service providers can help you pull out the most significant insights from your data.
What does it mean to build a pipeline?
A bioinformatic or analytical pipeline is a set of analytical steps executed in a predefined sequence to simplify and analyze large and complex biological datasets. Building a pipeline is the process of developing algorithms and testing the individual components to determine the optimal order of execution to produce robust, understandable, and reproducible results.
What is the difference between a programmer and software developer?
A software developer works with the client to develop the project idea, designs the software, and codes the programs involved in the software. The software developer is also involved in the deployment, applications, and maintenance of the software.
What is custom tailored software?
- Custom-tailored software is software that is built specifically for a client’s needs and tasks. There are many advantages to having custom-tailored software built, including increased efficiency, scalability of tasks, and flexibility in what the software can do specific to your needs.
What are the steps of having custom tailored software built?
- Step 1: Work with full-stack software engineers to outline the project goals.
- Step 2: Application development, where the software developers create the programs, pipelines, and applications that will comprise the custom software.
- Step 3: Finally is application deployment, where the finished software is used by the client and carefully maintained by the software developer.
What are the steps of having custom tailored software deployed?
- Step 1: Testing the software at scale and in real-world conditions.
- Step 2: Monitoring the software’s performance.
- Step 3: Maintaining the software, including making any adjustments or additions over time.
How do you maintain applications after deployment?
Maintenance of custom software is one of the most valuable services gained when outsourcing custom-tailored software development, after the software development itself. The team responsible for designing and deploying the software will monitor its performance, ensure it is meeting your needs, and fix any problems that arise. Having a dedicated team for monitoring your new software allows you to focus on your projects and goals while the technical details are handled by our experts.
What is cloud infrastructure versus on-premise infrastructure?
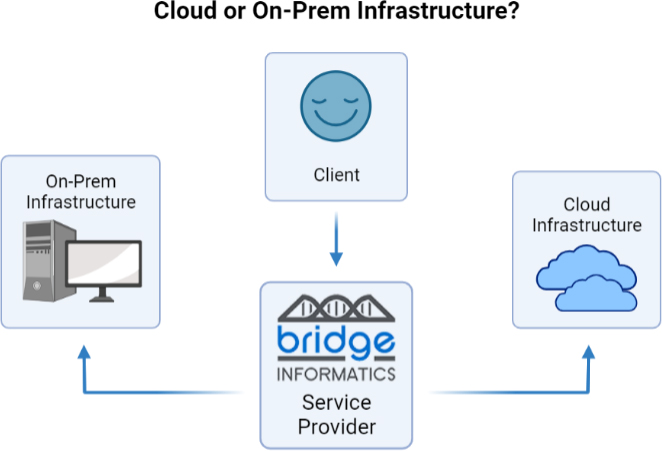
Cloud infrastructure is where software and applications are hosted offsite, in the ‘cloud’- in other words, virtually, on a third-party cloud-based server. This is in contrast to traditional on-premise infrastructure, where applications and software are hosted on the client or service provider’s servers and infrastructure.
What are the different cloud platforms?
There are a huge variety of cloud platforms available, but here at Bridge Informatics, we primarily use:
- AWS: Amazon Web Services, one of the world’s most commonly used cloud platforms.
- Azure: Microsoft Azure, Microsoft’s public cloud computing platform.
- GCP: Google Cloud Platform, Google’s suite of cloud computing services that uses the same infrastructure that Google uses internally.
What are the benefits of custom Cloud solutions?
- Scalability: Custom cloud computing solutions are a great way to scale up from your existing on-premise infrastructure while saving the time and money associated with setting up more physical infrastructure.
- Flexibility: Custom cloud solutions are extremely flexible, and can be scaled up or down and adjusted to a client’s needs as they change over time.
- Security: Data protection is critically important, and there are excellent security measures in place for cloud computing to protect your data.
- Centralization: A huge appeal of custom cloud computing solutions is that data, software, and other critical services you have stored in the cloud can be accessed quickly and easily remotely from a single, centralized location.
What are Automated Workflows?
Automated workflows are essentially the individual tasks within an analytical pipeline that perform all of the necessary steps for one part of the analytical pipeline. Automated workflows improve the consistency and reproducibility of data analysis by allowing the same type of data to be analyzed identically every time.
What are the benefits of Automated Workflow?
- Reproducibility and Reliability: Automated workflows help standardize your outputs after analyzing your raw data to improve the reducibility of your results.
- Saving time: Once an automated workflow is developed and tested, the efficiency of that step in your analysis process is greatly increased.
- Scalability: Increased efficiency means you can scale up your project and data analysis, allowing for better quality results, statistics, and more.
Why do you need Automated Workflow or Pipeline development?
Automated workflow and custom pipeline development is a highly specialized tasks, which is why you need a service provider like Bridge Informatics to undertake these development tasks for you. Having a service provider create your automated workflows and pipelines saves you time while ensuring your pipeline is of the highest quality.
What are the differences between Custom Cloud and Local Pipelines?
Bridge Informatics’ pipelines are second-to-none and can be run either on-premise on our servers or cloud-based platforms. If you don’t have a cloud computing infrastructure, we can create a custom cloud set-up to meet your needs.